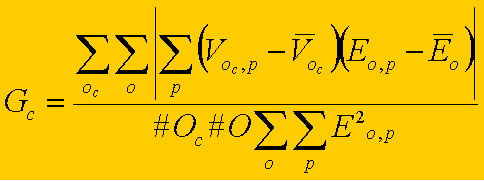|
The function to maximize in
the input phases is a normalized covariance between candidate activation and
network error. G for each candidate c is an absolute covariance
between candidate activation and network error, standardized by the number of
outputs for the candidate (#Oc), the number
of outputs in the target network (#O), and the squared error in the
target network summed across outputs o and patterns p. V
is the actual output activation of candidate c for pattern p.
Mean V is the mean output activation for candidate c. E
is the target-network error at output o for pattern p. Mean E
is the mean target-network error at output o. The products between
candidate activation deviance and error deviance are summed over patterns p.
The absolute value of that sum is then summed over network outputs o
and candidate outputs oc.
|